DevOps Roadmap 2026: Complete Step-by-Step Guide for Beginners to Senior Engineers
Many people search for "what is a DevOps roadmap" before they know where to begin. Simply put, a DevOps roadmap is the structured path from beginner to job-ready DevOps professional, and this guide covers it fully.
DevOps is one of the most in-demand disciplines in the world right now. In Nepal, the talent supply cannot keep up with what companies are hiring for. That gap creates a genuine window of opportunity for anyone willing to follow a structured, serious learning path.
This guide covers the complete DevOps roadmap 2026, from Linux fundamentals all the way through Kubernetes, service mesh, observability, and DevSecOps. You will also find Nepal-specific salary data, job market analysis, certification guidance, and a phase-by-phase timeline you can actually use.
Whether you are a student picking a first technical track, a sysadmin ready to modernize your skills, or a developer who wants to own the full software delivery cycle, the roadmap below gives you everything you need to move forward.
What Is a DevOps Roadmap?
A DevOps roadmap is a structured, sequential learning path that takes someone from foundational computing knowledge through to the advanced tools and practices that make modern software delivery work. It is not a random list of technologies it is a specific order of learning where each phase builds directly on the last.
The concept matters because DevOps as a field is extremely broad. Without a roadmap, most learners spend months jumping between tutorials, picking up shallow knowledge of dozens of tools without mastering any of them. A properly sequenced roadmap stops that from happening. So to learn more and understand what is Devops you can see our following blog.
What Is a DevOps Engineer Roadmap Exactly?
The roadmap of a DevOps engineer covers three layers:
- Technical skills, the tools and technologies you need to operate: Linux, Docker, Kubernetes, Terraform, AWS, CI/CD pipelines, monitoring stacks, and security practices.
- Conceptual understanding of why systems are designed the way they are, how different tools relate to each other, and what problems each one is solving.
- Operational mindset: how to think about reliability, failure, deployment risk, and system health the way experienced engineers do.
A complete DevOps engineer roadmap takes you through all three layers progressively. By the end, you are not just running commands, you are making architectural decisions and owning outcomes. To understand exactly what this role involves day to day, our breakdown of core technical competencies every DevOps practitioner needs covers the full skill landscape in detail.
What Do DevOps Engineers Do Day to Day?
A DevOps engineer sits at the intersection of software development and IT operations. Their job is to make sure software moves from a developer's laptop to production reliably, at speed, and without breaking things.
In practice, what do DevOps engineers do? Their typical week includes:
- Writing and maintaining CI/CD pipelines that automatically test, build, and deploy code
- Managing cloud infrastructure on AWS, Azure, or GCP
- Containerizing applications and managing Kubernetes clusters
- Writing Infrastructure as Code with Terraform and Ansible
- Setting up and responding to monitoring alerts from Prometheus and Grafana
- Working with development teams to debug deployment failures and improve release velocity
- Running postmortems after incidents to prevent the same failure from happening twice
- Reviewing security scanning results from tools like Trivy or Snyk
- Handling on-call rotations and maintaining SLAs for critical systems
The role requires both technical depth and strong cross-team communication. A DevOps engineer who cannot talk to developers, product managers, and operations staff is limited. The job is as much about removing organizational friction as it is about running tools.
Why DevOps Is Important in 2026
Understanding why DevOps is important helps you talk about it confidently in interviews and helps you make smarter decisions about what to learn first.
Before DevOps became standard practice, software releases were slow and painful. Development teams would write code for weeks or months, hand it to operations teams to deploy, and then watch things break in ways that nobody had anticipated. Debugging production failures was slow, deployments happened quarterly, and teams blamed each other when things went wrong.
DevOps solved this by treating development and operations as a shared responsibility. Automated testing catches problems before they reach production. CI/CD pipelines deploy changes daily instead of quarterly. Infrastructure as Code means environments are consistent and reproducible. Monitoring gives teams real-time visibility into what is actually happening.
The result: faster software delivery, fewer production incidents, shorter recovery times when incidents do happen, and teams that work together rather than against each other.
Why DevOps is important, specifically in 2026, comes down to scale. Every company, bank, hospital, e-commerce platform, fintech startup, and government service now runs on software. That software must be delivered continuously, updated frequently, and kept running reliably 24/7. DevOps is the only approach that makes that possible at a modern scale.
Is DevOps in Demand Right Now?
Yes and not just globally. Is DevOps in demand in Nepal? Absolutely. DevOps engineers are now among the highest-paid IT professionals across the entire sector, with roles spanning Cloud Engineer, Site Reliability Engineer, Platform Engineer, and Infrastructure Engineer.
The demand continues to grow because:
- Cloud adoption is still accelerating across all industries
- Every company that adopted cloud 3–5 years ago now needs engineers to operate and mature those environments
- AI-powered development tools are increasing developer output, which increases the need for reliable deployment infrastructure
- The DevSecOps and Platform Engineering specializations have created entirely new hiring categories
The talent gap in Nepal is particularly significant. Companies here are hiring, and many qualified DevOps engineers work remotely for international clients, earning much more than local market rates without leaving Kathmandu.
DevOps vs Agile vs Scrum: How They Relate
This question comes up constantly, so it deserves a direct answer.
- Agile is a product development philosophy that breaks work into short cycles (sprints), values working software over documentation, and treats requirements as evolving rather than fixed.
- Scrum is a specific Agile framework with defined roles (Product Owner, Scrum Master, Development Team), events (Sprint Planning, Daily Standup, Sprint Review), and artifacts (Product Backlog, Sprint Backlog).
- Kanban is another Agile method that visualizes work in progress, limits the number of tasks in each stage, and focuses on continuous flow rather than fixed sprints.
- DevOps is the technical and cultural practice that makes Agile possible at speed. Agile teams decide what to build and how to prioritize it. DevOps provides the automation and infrastructure that lets those teams ship their decisions to production quickly and safely.
For a deeper look at how these methodologies interact in practice, the comparison between DevOps and Agile ways of working unpacks where they overlap and where they diverge.
In practice, most DevOps engineers work in Agile environments and participate in Scrum ceremonies. Understanding how Kanban boards, sprint backlogs, and standup culture work is genuinely useful, not because DevOps is Agile, but because you will work alongside Agile teams every day.
The Full DevOps Roadmap 2026 Phase by Phase
This is the complete DevOps full roadmap broken into 12 phases. Each phase has an estimated study time assuming 2–3 hours of hands-on practice per day. Do not treat these as rigid your pace depends on your background and how deeply you practice each phase.
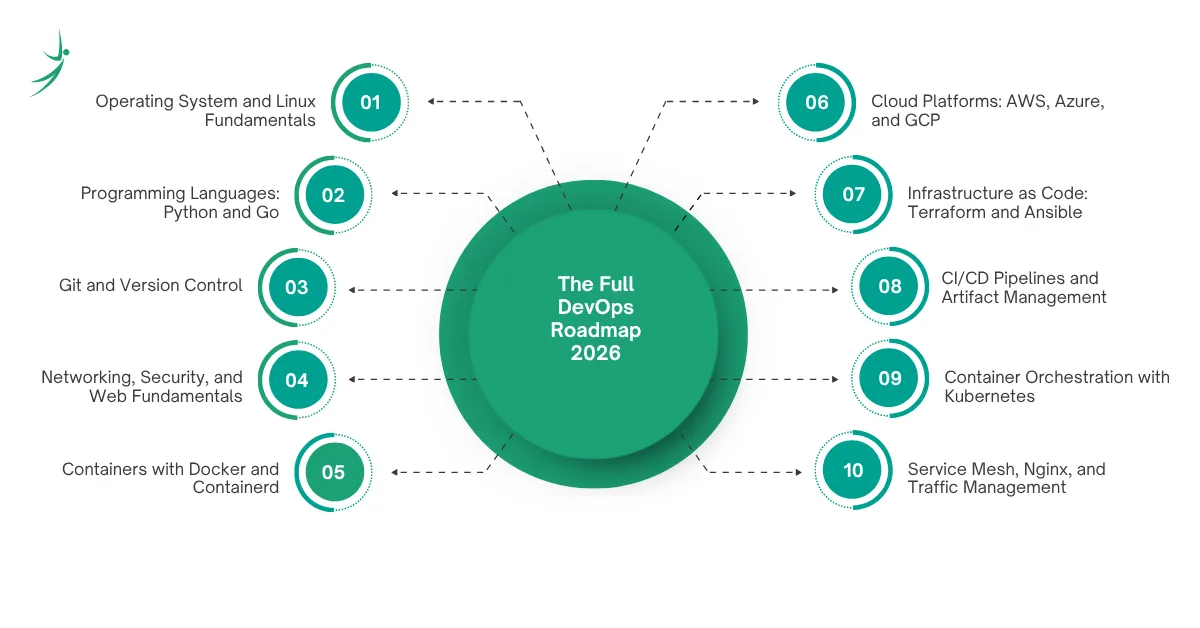
Phase 1 – Operating System and Linux Fundamentals
Estimated time: 3–5 weeks
The operating system layer is where everything in DevOps ultimately runs. Cloud servers run Linux. Containers run on Linux kernels. Kubernetes nodes run Linux. Before you touch a single DevOps tool, you need genuine comfort in a Linux terminal, not just knowing commands, but understanding what is actually happening when you run them.
What to learn:
- Terminal navigation: directories, file paths, reading and editing files with vim or nano
- File permissions: chmod, chown, read/write/execute, why permissions matter in production
- User and group management: creating users, managing access, sudo and privilege escalation
- Process management: ps, top, htop, kill, background processes, service management with systemctl
- Package management: apt (Debian/Ubuntu) and yum/dnf (RHEL/CentOS)
- Disk and storage: mounting filesystems, checking disk usage, df, du, lsblk
- Log management: /var/log/, journalctl, reading application logs
- Cron jobs: scheduling automated tasks
- Shell environment: .bashrc, environment variables, PATH, export
- SSH: connecting to remote servers, key-based authentication, scp, rsync
The operating system is the foundation of the roadmap of a DevOps engineer. Engineers who skip this phase struggle to debug production issues when tools fail and the only thing available is a terminal.
Practice: Set up a free Ubuntu VM locally using VirtualBox or VMware, or spin up a free-tier EC2 instance on AWS. Do everything through the terminal resist the GUI.
Phase 2 – Programming Languages: Python and Go
Estimated time: 3–5 weeks
DevOps engineers are not software developers, but they write code every day. Automation scripts, pipeline configurations, infrastructure modules, monitoring integrations all of this requires real programming ability.
Python is the primary language for most DevOps automation work. It is readable, has an enormous standard library, and integrates natively with every major cloud platform and DevOps tool. Focus on:
- Data types, control flow, functions, modules
- File I/O and working with JSON and YAML
- Making HTTP requests with the requests library
- Working with the boto3 SDK for AWS automation
- Writing CLI scripts for repetitive DevOps tasks
- Error handling and writing maintainable scripts (not just throw-away one-liners)
Go (Golang) has become increasingly important as a DevOps programming language. Kubernetes is written in Go. Terraform is written in Go. Many modern cloud-native tools are written in Go. You do not need Go to get your first job, but understanding it gives you the ability to read and contribute to the tools you use every day.
Start with Python. Add Go after you are comfortable with the DevOps tools themselves.
Phase 3 – Git and Version Control
Estimated time: 1–2 weeks
Git is the foundation of every DevOps workflow. Every CI/CD pipeline starts with a Git event a commit, a pull request, a tag. Every Infrastructure as Code change is tracked through Git. GitOps literally treats Git as the source of truth for production state.
Focus on:
- Core concepts: staging, committing, branches, merging, rebasing
- Branching strategies: feature branches, trunk-based development, Gitflow
- Pull requests and code review workflows on GitHub, GitLab, or Bitbucket
- Resolving merge conflicts
- Tagging releases and using semantic versioning
- Git hooks for automated checks before commits reach the repository
- Working with .gitignore to keep secrets and generated files out of version control
GitHub is the dominant platform for open-source projects and most tech companies. GitLab is more common in enterprise environments and has a deeply integrated CI/CD system. Bitbucket is used heavily in organizations running the Atlassian stack (Jira, Confluence). Know GitHub well; understand that GitLab and Bitbucket follow the same principles with different interfaces.
Phase 4 – Networking, Security, and Web Fundamentals
Estimated time: 2–3 weeks
Network and security knowledge is the most common gap in DevOps engineers who learned purely from tutorials. Understanding why systems cannot talk to each other, how traffic actually flows, and where security controls sit — this is what separates engineers who can debug production issues from engineers who cannot.
Core networking concepts:
- IP addressing: IPv4, subnets, CIDR notation, private vs public IP ranges
- DNS: how domain names resolve, A records, CNAME, TTL, and why DNS caching causes problems
- HTTP and HTTPS: request/response cycle, status codes, headers, TLS certificates
- TCP vs UDP: when each is used and why it matters for monitoring and troubleshooting
- Ports and firewalls: common ports (22, 80, 443, 3306, 5432), iptables, security group rules
- Load balancers: how Layer 4 and Layer 7 load balancing differ, health checks, sticky sessions
- Nginx: understanding reverse proxy configuration, serving static files, SSL termination, upstream proxy to applications Nginx appears in nearly every production environment.
- Apache: still present in many legacy deployments; understanding VirtualHost configuration and .htaccess is practically useful
Security fundamentals:
- PKI basics: certificates, certificate authorities, how TLS works
- SSH key management and hardening
- Principle of least privilege
- Network segmentation and why it matters
This knowledge becomes critical when you are debugging Kubernetes networking, configuring AWS security groups, or figuring out why a container cannot reach a database.
Phase 5 – Containers with Docker and Containerd
Estimated time: 3–4 weeks
Containers changed how software is packaged and deployed. Instead of configuring servers manually and hoping they match what development tested on, you package your application and everything it needs into a container image. That image runs identically everywhere.
Docker remains the primary tool for learning containers. Focus on:
- Writing Dockerfiles: base images, layers, RUN, COPY, EXPOSE, CMD, ENTRYPOINT
- Building, tagging, and pushing images to a container registry (Docker Hub, Amazon ECR, GitHub Container Registry)
- Running containers locally and inspecting their state
- Docker Compose for multi-container local development (application + database + cache)
- Image optimization: minimizing layer count, using multi-stage builds, choosing slim base images
- Container networking: bridge networks, host networking, container-to-container communication
- Volume management: persisting data between container restarts
Containerd is the container runtime that Kubernetes actually uses under the hood. Docker historically used containerd as its runtime, and understanding that containerd is the industry standard runtime (not Docker itself) matters when you move into Kubernetes administration.
Podman is a daemonless Docker alternative that is increasingly adopted in enterprise Linux environments (especially RHEL/CentOS). It is worth knowing it exists and understanding why organizations prefer it.
After this phase, containers stop being abstract. You understand why Kubernetes exists when you have thousands of containers to run across hundreds of servers; something has to schedule, restart, and route traffic to them automatically.
Phase 6 – Cloud Platforms: AWS, Azure, and GCP
Estimated time: 4–6 weeks
Modern infrastructure lives in the cloud. Physical servers in company data centres are being replaced by cloud-managed compute, storage, networking, and managed services. The three major public cloud providers are AWS, Microsoft Azure, and Google Cloud Platform (GCP).
For most people, AWS is the right starting point. It holds the largest market share, appears most frequently in Nepal's job listings for DevOps roles, has the deepest documentation, and offers the most recognized certifications. If your target employer specifically uses Azure or GCP, start there the concepts transfer.
Core concepts to master (on whichever provider you choose):
Compute
- EC2 instances: launching, sizing, key pairs, security groups
- Auto Scaling Groups: defining minimum/maximum capacity, scaling policies
- Lambda functions: event-driven serverless execution and when it makes sense
Networking
- Virtual Private Cloud (VPC): subnets (public/private), route tables, NAT gateways, internet gateways
- Security Groups and Network ACLs: how traffic is filtered at instance and subnet level
- Elastic Load Balancing: Application Load Balancer (ALB) vs Network Load Balancer (NLB)
- Route 53: DNS management, health checks, routing policies
- CloudFront: CDN for static assets and API acceleration
Storage
- S3: object storage, bucket policies, versioning, lifecycle rules, static website hosting
- EBS: block storage attached to EC2 instances
- EFS: shared network file storage
Identity and Access Management (IAM)
- Users, groups, roles, and policies
- Principle of least privilege in IAM design
- Instance roles vs user access keys when to use each
- MFA enforcement and account-level security controls
Managed Databases
- RDS: managed relational databases (PostgreSQL, MySQL)
- DynamoDB: managed NoSQL
- ElastiCache: managed Redis/Memcached
Reach a point where you can build a working cloud environment VPC, public/private subnets, an EC2 instance, an RDS database, S3 storage, proper IAM roles without referencing step-by-step guides. That level of fluency is what job interviews test.
Phase 7 – Infrastructure as Code: Terraform and Ansible
Estimated time: 4–5 weeks
Clicking through cloud consoles to build infrastructure is not repeatable and cannot be version-controlled. Infrastructure as Code (IaC) means defining your infrastructure in code files so it can be versioned, reviewed in pull requests, shared across teams, and rebuilt identically on demand.
Terraform is the dominant IaC tool for cloud infrastructure provisioning. You define resources in .tf files using HCL (HashiCorp Configuration Language), and Terraform creates, updates, or destroys cloud resources to match your definition. It works across AWS, Azure, GCP, and dozens of other providers.
Learn:
- Terraform providers, resources, and data sources
- Input variables and output values
- State management: why Terraform state exists, storing it remotely in S3 with DynamoDB locking
- Modules: writing reusable infrastructure components
- Workspaces: managing multiple environments (dev, staging, prod)
- terraform plan as a mandatory review step before terraform apply
- Import existing infrastructure into Terraform management
- Cost estimation with terraform plan and tools like Infracost
Ansible handles configuration management making sure the software running on your servers is installed, configured, and in the correct state. Where Terraform provisions infrastructure, Ansible configures what runs on it.
Learn:
- Inventory: defining the hosts Ansible manages
- Playbooks: YAML-defined sequences of tasks
- Roles: organizing playbooks into reusable, shareable components
- Jinja2 templates for dynamic configuration files
- Handlers: tasks that run only when a previous task changes something
- Ansible Vault: encrypting sensitive variables like passwords and API keys
This phase is where the DevOps mindset becomes real. Infrastructure is no longer something you build by hand once and pray never changes it is something you define, version-control, and recreate on demand.
Phase 8 – CI/CD Pipelines and Artifact Management
Estimated time: 3–4 weeks
CI/CD stands for Continuous Integration and Continuous Deployment. It is the automation system that takes code from a developer's commit, runs it through tests, builds a deployable artifact, and ships it to production without anyone pressing a manual deploy button.
This is one of the highest-value skills on the DevOps roadmap because every company, regardless of size, needs it.
Continuous Integration (CI): Every time a developer pushes code, a pipeline automatically runs:
- Unit tests and integration tests
- Static code analysis and linting (tools like SonarQube check code quality)
- Security scanning (checking dependencies for known vulnerabilities)
- Docker image building
Continuous Deployment (CD): When CI passes, the pipeline:
- Pushes the Docker image to an artifact registry (JFrog Artifactory, Amazon ECR, GitHub Container Registry, or Nexus Repository)
- Deploys the new image to staging automatically
- Runs end-to-end tests against staging
- Promotes to production (automatically in full CD, or with a manual gate in CD with approval)
Artifact registries (JFrog Artifactory, Nexus Repository Manager, and AWS ECR) are where built artifacts Docker images, compiled binaries, npm packages, Python wheels are stored between pipeline stages. Understanding how artifact registries work, how to version artifacts, and how to manage retention policies is a practical CI/CD skill that many tutorials skip.
Major CI/CD platforms in 2026:
- GitHub Actions: Built into GitHub, excellent free tier, enormous community of reusable actions, becoming the default for most modern teams
- GitLab CI/CD: Deeply integrated into GitLab, highly configurable, strong for enterprise self-hosted deployments
- Jenkins: Older but still dominant in enterprise environments; understanding Jenkins pipelines (Jenkinsfile) is still required in many job descriptions
- Argo CD: GitOps-native CD tool for Kubernetes; treats Git as the source of truth for deployed state
Practical project: Build a complete pipeline from scratch. Code commit → tests → Docker build → push to ECR → deploy to a Kubernetes cluster. Have this running and documented in your GitHub profile.
Phase 9 – Container Orchestration with Kubernetes
Estimated time: 6–8 weeks
Kubernetes is the most important single tool on the DevOps roadmap. It is complex, has a steep learning curve, and is completely worth the time investment.
At its core, Kubernetes manages containers at scale. It schedules containers across a cluster of servers, restarts them when they crash, routes traffic to healthy instances, rolls out updates without downtime, and scales up automatically under increased load.
Core Kubernetes concepts:
- Pods: The smallest deployable unit; one or more containers sharing a network namespace
- Deployments: Managing pod replicas, rolling updates, and rollback
- Services: Exposing pods within the cluster (ClusterIP), to other services (NodePort), or to the internet (LoadBalancer)
- Namespaces: Logical isolation within a cluster for different teams or environments
- ConfigMaps and Secrets: Externalizing application configuration and sensitive data
- Persistent Volumes and Persistent Volume Claims: Stateful storage for databases and file systems
- Ingress: Routing external HTTP/HTTPS traffic to services based on hostname or path
- Horizontal Pod Autoscaler (HPA): Automatically scaling pods based on CPU or custom metrics
- StatefulSets: Managing stateful applications like databases that require stable network identities
- DaemonSets: Running a pod on every node (for monitoring agents, log collectors)
- RBAC (Role-Based Access Control): Defining who can do what inside a Kubernetes cluster
- Helm charts: Packaging Kubernetes applications for repeatable deployment
- Kustomize: Customizing Kubernetes manifests without forking them
Managed Kubernetes services:
- Amazon EKS (Elastic Kubernetes Service): AWS's managed K8s offering
- Google GKE (Google Kubernetes Engine): Often considered the most mature managed K8s platform
- Azure AKS (Azure Kubernetes Service): Microsoft's managed K8s offering
Practice on managed services they eliminate the complexity of managing the control plane and mirror real production environments.
Phase 10 – Service Mesh, Nginx, and Traffic Management
Estimated time: 2–3 weeks
Once applications run inside Kubernetes, managing traffic between services becomes its own engineering problem. At small scale, Kubernetes Services handle it. At larger scale many services, complex routing rules, mTLS between services, traffic splitting for canary deployments you need a service mesh.
Service mesh: A service mesh is a dedicated infrastructure layer for managing service-to-service communication. Instead of each application implementing its own retry logic, circuit breaking, and mTLS encryption, the service mesh handles all of that transparently via sidecar proxies injected into each pod.
- Istio is the most widely adopted service mesh. It provides traffic management (weighted routing, canary deployments, A/B testing), mutual TLS (mTLS) for encrypted service-to-service communication, and deep observability (request traces, latency metrics per service).
- Linkerd is a lighter-weight alternative to Istio, easier to operate, and increasingly popular for teams that want service mesh benefits without Istio's operational complexity.
Nginx in Kubernetes: Nginx remains central to DevOps work in two forms:
- As a reverse proxy and web server for serving applications directly
- As the Nginx Ingress Controller inside Kubernetes, which is the most commonly deployed Kubernetes Ingress implementation
Understanding Nginx upstream configuration, proxy headers, SSL termination, rate limiting, and WebSocket proxying is practical knowledge that appears in real environments constantly.
Traffic management patterns:
- Blue/green deployments: running two production environments simultaneously, switching traffic between them
- Canary releases: sending a small percentage of traffic to a new version before full rollout
- Circuit breakers: automatically stopping requests to a failing service to prevent cascade failures
- Retry logic and timeout policies
Phase 11 – Monitoring, Observability, and Incident Management
Estimated time: 3–4 weeks
Once applications run in production, you need to know immediately when something breaks and ideally, know why before users start reporting problems. Observability covers three pillars: metrics, logs, and traces.
Metrics with Prometheus and Grafana:
- Prometheus scrapes metrics from your applications and infrastructure at regular intervals, stores them as time-series data, and evaluates alerting rules
- Grafana visualizes Prometheus metrics in dashboards CPU usage, request latency, error rates, deployment frequency
- Learn PromQL (Prometheus Query Language) for writing effective queries and alert rules
- Set up AlertManager to route alerts to Slack, PagerDuty, or email based on severity
Logs with the ELK Stack and Loki:
- ELK Stack: Elasticsearch (storage and search), Logstash (ingestion and parsing), Kibana (visualization). The industry standard for centralized log management, especially in enterprise environments
- Loki: A lighter-weight log aggregation system designed to work natively with Grafana. Far cheaper to operate than ELK for teams already using Prometheus and Grafana
- Fluentd and Fluent Bit: log shipping agents that collect logs from containers and forward them to ELK or Loki
Distributed tracing:
- Jaeger and Zipkin: trace requests as they move through microservices, helping identify which service is causing latency
- OpenTelemetry: the emerging standard for instrumenting applications with traces, metrics, and logs using a single, vendor-neutral SDK
Incident management the part most roadmaps skip:
Monitoring without a response process is just noise. Real DevOps operations include:
- On-call rotations: using tools like PagerDuty or OpsGenie to route alerts to the engineer on duty
- Incident response runbooks: documented procedures for known failure modes so on-call engineers can resolve common incidents without waking up senior staff
- Postmortems (blameless): structured analysis of what went wrong, the timeline, contributing factors, and action items to prevent recurrence done without assigning individual blame
- SLAs, SLOs, and SLIs: Service Level Agreements (contractual commitments), Service Level Objectives (internal targets), and Service Level Indicators (the metrics you measure) understanding this framework is expected at mid-level and above
DORA Metrics how DevOps performance is measured:
- Deployment frequency
- Lead time for changes
- Mean Time to Recovery (MTTR)
- Change failure rate
These four DORA metrics are the industry standard for measuring whether DevOps practices are actually improving delivery performance. Senior engineers talk in these terms.
Phase 12 – Security, DevSecOps, and Shift-Left Practices
Estimated time: 2–3 weeks
Security used to be something added at the end of a release cycle. DevSecOps changes that by building security into every stage of the development and deployment process from code commit through to production. Shift-left security means catching security issues earlier in the development process, where they are cheaper and faster to fix.
Key DevSecOps practices:
In CI/CD pipelines:
- SonarQube: static code analysis, identifying bugs, security vulnerabilities, and code smells before code reaches production
- Trivy: scanning container images for known CVEs (Common Vulnerabilities and Exposures) before they are pushed to production registries
- Snyk: scanning application dependencies for vulnerabilities and suggesting fixes
- Gitleaks / TruffleHog: detecting secrets (API keys, passwords) accidentally committed to Git repositories
In infrastructure:
- HashiCorp Vault: centralized secrets management storing and rotating database passwords, API tokens, and TLS certificates without hardcoding them in configuration files or environment variables
- AWS Secrets Manager / Parameter Store: cloud-native alternatives to Vault for AWS-heavy environments
- OPA (Open Policy Agent): enforcing policies on Kubernetes deployments (preventing containers from running as root, requiring resource limits, etc.)
Kubernetes security hardening:
- Pod Security Standards: restricting what containers can do inside a cluster
- Network Policies: controlling which pods can communicate with each other
- Image signing and verification with Cosign
- RBAC: ensuring no service account has more permissions than it needs
The shift-left security mindset changes how DevOps engineers think about their pipelines. Security gates are not blockers they are automated quality checks, the same as unit tests. They run on every commit, fail fast, and give developers specific, actionable feedback.
Which DevOps Tool Is in Demand in 2026?
A practical question with a data-backed answer. Which DevOps tool is in demand changes over time here is what job listings, hiring managers, and the community consistently point to right now.
| Category | In-Demand Tools (2026) |
|---|---|
| OS / Foundation | Linux (Ubuntu, RHEL), Bash, Python |
| Version Control | Git, GitHub, GitLab, Bitbucket |
| Containers | Docker, Podman, Containerd |
| Orchestration | Kubernetes, Amazon EKS, GKE, AKS |
| Cloud | AWS (dominant), Azure, GCP |
| IaC | Terraform, Ansible, Pulumi |
| CI/CD | GitHub Actions, GitLab CI, Jenkins, Argo CD |
| Web / Proxy | Nginx, Apache |
| Artifact Registry | Amazon ECR, JFrog Artifactory, Nexus, GitHub Packages |
| Monitoring | Prometheus, Grafana, Datadog |
| Logging | Loki, ELK Stack (Elasticsearch, Logstash, Kibana) |
| Tracing | Jaeger, OpenTelemetry |
| Security | Trivy, Snyk, HashiCorp Vault, SonarQube |
| Service Mesh | Istio, Linkerd |
| GitOps | Argo CD, Flux |
| Programming | Python, Go (Golang) |
For a curated breakdown of where each of these tools fits in the broader ecosystem, our guide on the automation and infrastructure tools that define modern engineering teams covers each category in depth.
If you had to pick three areas for the highest job market return in Nepal right now: Kubernetes + AWS + CI/CD. Master those three and you are hireable. The rest deepens your value over time.
DevOps Career Path: From Junior to Senior Engineer
The DevOps career path has clear stages, each with different skill expectations, responsibilities, and salary ranges.
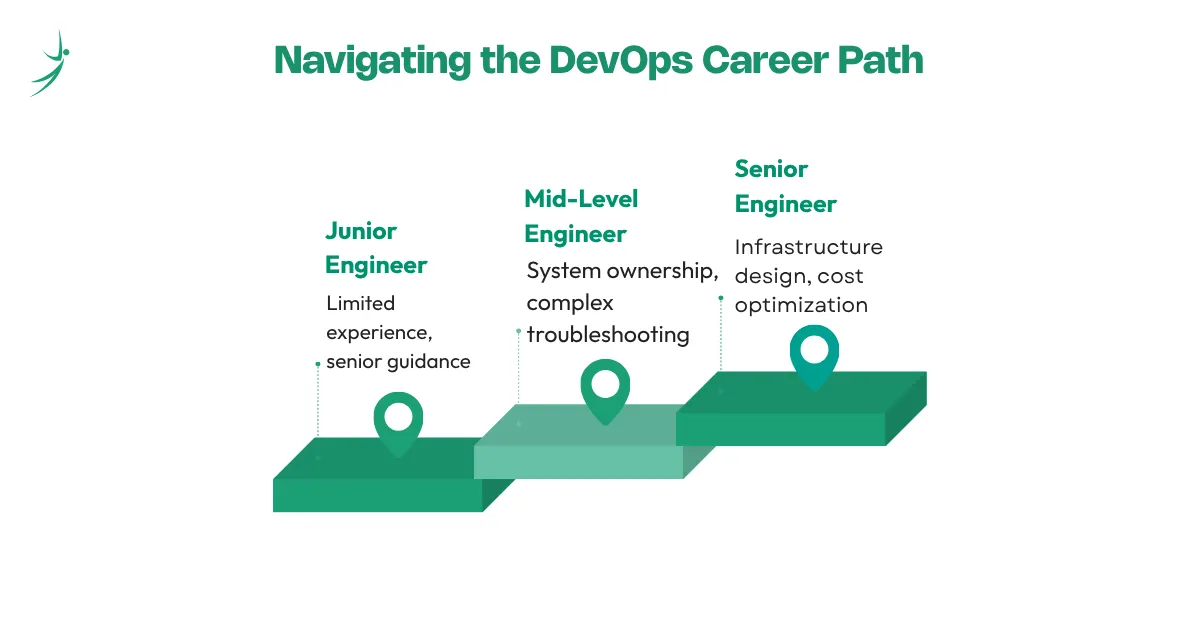
Junior DevOps Engineer
Experience: 0–2 years
At this level, you work under senior guidance. You pick up tickets, maintain existing pipelines, help with monitoring, write scripts, and gradually take ownership of smaller systems. You are expected to know Linux, Git, Docker, and at least one cloud provider at a working level.
What gets you hired at this level in Nepal:
- Completed a structured training program with hands-on projects
- GitHub profile with working Dockerfiles, Terraform configs, or pipeline examples
- At least one cloud certification (AWS Cloud Practitioner or Solutions Architect Associate)
- Ability to explain what a CI/CD pipeline does and sketch a basic one
Mid-Level DevOps / Cloud Engineer
Experience: 2–5 years
Here you own systems independently. You can design a CI/CD pipeline from scratch, troubleshoot Kubernetes issues at the pod and node level, write Terraform modules used by your team, and lead incident response. You have strong opinions about architecture based on things that went wrong in production.
Cloud certifications become genuinely valuable at this stage AWS Solutions Architect Professional, CKA, or Terraform Associate help you pass screening at larger companies.
Salary at this level in Nepal: NPR 80,000–150,000/month for local roles; significantly higher for remote international positions.
Senior DevOps / Platform Engineer / SRE
Experience: 5+ years
Senior engineers lead infrastructure design, set technical direction, mentor junior staff, and own reliability at a systems level. They make architectural decisions about multi-region deployments, design disaster recovery strategies, manage cloud cost optimization initiatives (reducing spend without sacrificing performance), and bridge the gap between product and infrastructure.
Cost optimization becomes a real responsibility at senior level designing systems that are not just reliable but financially efficient. Senior engineers actively use AWS Cost Explorer, Reserved Instances strategies, Spot instance integration, and Savings Plans to reduce cloud spend.
Senior DevOps engineers with 5+ years of experience earn between NPR 150,000 and NPR 350,000+ per month in Nepal, with remote international roles paying significantly more.
DevOps Career Roadmap: Soft Skills and Team Culture
The technical side of the DevOps career roadmap gets most of the attention. The soft skills side is what separates engineers who advance quickly from those who plateau.
- Communication: DevOps engineers translate between developers, product managers, security teams, and business stakeholders. Being able to explain a complex infrastructure failure in plain language, or justify a tooling choice to a non-technical manager, is a real career skill.
- Collaboration: DevOps emerged specifically because siloed teams failed. The people who thrive in DevOps roles are the ones who actively share knowledge, document what they build, write runbooks that others can follow, and treat other teams as partners rather than blockers.
- On-call culture: Being effective on call means staying calm under pressure, methodically following runbooks, knowing when to escalate, and writing thorough postmortems. This is trainable, not innate.
- Open source participation: Contributing to open-source projects even small documentation fixes or bug reports builds your reputation, teaches you how mature codebases are managed, and gives you topics to discuss in interviews.
- Continuous learning mindset: DevOps tooling moves fast. Kubernetes releases three times per year. New cloud services launch constantly. Engineers who build the habit of following release notes, reading engineering blogs, and doing small experiments with new tools stay relevant. Engineers who stop learning after getting a job do not.
DevOps Roadmap in Nepal: Full Local Guide
Why DevOps Is Important for Nepal's IT Sector
Understanding why DevOps is important in the Nepali context gives you a clearer picture of the opportunity.
Nepal's IT sector is growing faster than most people realize. IT exports have surpassed $1 billion annually. Companies in Kathmandu, Lalitpur, and Pokhara are scaling, and the pressure to ship software faster, reduce downtime, and maintain international-standard infrastructure is growing alongside client expectations.
Local companies that used to deploy manually once a month are being asked by international clients to deploy multiple times per day. Banks running core banking systems cannot afford the kind of production incidents that come from manual deployments and no monitoring. Fintech startups need cloud infrastructure that scales automatically during peak usage without requiring someone to manually provision servers at midnight.
DevOps is the answer to all of those pressures. That is why DevOps is important specifically for Nepal's IT sector right now it is not just a global trend, it is a direct response to what Nepali IT companies are being asked to deliver.
DevOps Jobs in Nepal: Who Is Hiring?
Many IT companies in Nepal are actively hiring DevOps engineers. The categories of employers include:
- IT outsourcing and software services firms: Companies delivering software to international clients need DevOps infrastructure that meets Western enterprise standards. These firms hire DevOps engineers to build and maintain CI/CD pipelines, manage cloud environments, and ensure deployment reliability.
- Fintech and banking technology companies: Financial services require continuous availability, strict security controls, and auditable change management. DevOps engineers in fintech in Nepal work closely with compliance teams and implement DevSecOps practices.
- E-commerce and SaaS startups: Fast-growing Kathmandu-based product companies need engineers who can build infrastructure that scales with traffic spikes without over-provisioning resources.
- International companies hiring remotely: This is the biggest growth category for DevOps in Nepal. Foreign companies particularly from the US, UK, Australia, and Europe hire DevOps engineers from Nepal for remote roles. These positions pay significantly above local market rates while allowing engineers to work from home.
DevOps job in Nepal listings appear on MeroJob, JobsNepal, LinkedIn, and directly on company career pages. Remote DevOps job in Nepal opportunities are found on platforms like Toptal, Arc.dev, and direct LinkedIn outreach to international companies.
DevOps Salary in Nepal (2026 Data)
Here is a realistic picture of DevOps salary in Nepal across experience levels:
| Experience Level | Monthly Salary (NPR) | Notes |
|---|---|---|
| Entry (0–2 years) | 40,000 – 80,000 | Fresh from training with portfolio and 1 certification |
| Mid-level (2–5 years) | 80,000 – 150,000 | Hands-on K8s and cloud experience required |
| Senior (5+ years) | 150,000 – 350,000+ | Architecture ownership, team leadership |
| Remote (international clients) | 200,000 – 600,000+ | USD-denominated rates, highly variable |
(This data is taken from different sites like kumari jobs, necojobs etc)
The full annual range for DevOps in Nepal runs from approximately NPR 10 lakhs per year at entry level to NPR 60 lakhs per year for senior specialists and principal engineers working for international clients.
Skills that push salaries toward the higher end:
- Kubernetes expertise (especially at scale multi-cluster, multi-region)
- AWS certifications (Solutions Architect Professional, DevOps Engineer Professional)
- CKA (Certified Kubernetes Administrator)
- Terraform expertise with mature module architecture
- Platform Engineering experience building internal developer platforms
DevOps Nepal and the Remote Work Revolution
The remote work shift has fundamentally changed the DevOps career calculation in Nepal. Skilled DevOps engineers working remotely can earn much higher than local market rates, because their work is cloud-hosted, asynchronous, and entirely tool-mediated.
A DevOps engineer in Kathmandu doing the same work as a DevOps engineer in London is doing exactly the same job. More and more companies are recognizing this. DevOps Nepal is no longer just about local companies it is about connecting trained Nepali engineers with global demand.
This creates a specific strategy: train for international standards (AWS certification, CKA, production Kubernetes experience), build a visible GitHub portfolio, and target remote positions on platforms like LinkedIn, Toptal, or Arc.dev. The income ceiling this creates is dramatically higher than pure local market employment.
How Long Does the DevOps Full Roadmap Take?
The DevOps full roadmap, followed seriously, takes 8–12 months from zero to entry-level job-readiness with 2–3 hours of daily practice. Here is the phase breakdown:
| Phase | Topic | Estimated Duration |
|---|---|---|
| 1 | Linux and Operating Systems | 3–5 weeks |
| 2 | Python and Go | 3–5 weeks |
| 3 | Git and Version Control | 1–2 weeks |
| 4 | Networking and Security | 2–3 weeks |
| 5 | Docker and Containers | 3–4 weeks |
| 6 | Cloud Platforms (AWS) | 4–6 weeks |
| 7 | Terraform and Ansible | 4–5 weeks |
| 8 | CI/CD and Artifact Management | 3–4 weeks |
| 9 | Kubernetes | 6–8 weeks |
| 10 | Service Mesh and Nginx | 2–3 weeks |
| 11 | Monitoring and Incident Management | 3–4 weeks |
| 12 | DevSecOps and Shift-Left | 2–3 weeks |
| Total | ~36–52 weeks |
These estimates assume daily hands-on practice, not just passive watching. If you have a development or sysadmin background, cut the early phases significantly. If you are starting from zero, plan for the longer end.
The most important thing: phases are not fully sequential in practice. After Phase 5 (Docker), many learners start Phase 6 (Cloud) and Phase 7 (IaC) in parallel, bringing their Docker knowledge into cloud practice immediately
Best DevOps Certifications in 2026
Certifications do not replace hands-on experience, but they validate knowledge, help pass resume screening, and signal professional commitment. Here are the ones worth pursuing in 2026:
Tier 1: Highest return on investment:
- AWS Certified Solutions Architect Associate (SAA-C03): The most recognized cloud certification globally. Validates cloud architecture knowledge and design principles across AWS services.
- Certified Kubernetes Administrator (CKA): A hands-on exam from the Cloud Native Computing Foundation (CNCF). Tests real Kubernetes administration skills you work in a live cluster during the exam. Highly respected by employers.
- HashiCorp Terraform Associate: Validates Terraform proficiency. Increasingly listed as required or preferred in DevOps job descriptions.
Tier 2 — After landing your first role:
- AWS Certified DevOps Engineer Professional: Advanced certification covering CI/CD, IaC, monitoring, and incident management on AWS.
- Certified Kubernetes Application Developer (CKAD): Complements the CKA from the developer-focused angle.
- AWS Certified Security Specialty: Valuable if you move into DevSecOps.
- Google Associate Cloud Engineer: Worth pursuing if your role uses GCP.
For Nepal specifically: AWS certifications carry the clearest salary premium in local job listings. Engineers with AWS Certified Solutions Architect consistently report faster hiring timelines and higher starting offers. The CKA is the most impressive single certification you can hold in a Kubernetes interview.
DevOps Roadmap Reddit: What the Community Says
The devops roadmap reddit community primarily in r/devops and r/learnprogramming provides a useful reality check on what actually matters versus what roadmaps emphasize.
Recurring advice from practitioners:
- "Build something real and break it." The most consistent advice on devops roadmap reddit threads is to move past tutorials and build working projects. Break them deliberately. Fix them. The debugging experience is worth more than any course completion certificate.
- "Linux fundamentals are non-negotiable." Engineers who mention skipping Linux because they wanted to get to Kubernetes faster consistently report struggling. This pattern appears repeatedly in community discussions.
- "Kubernetes is hard but worth it." The CKA is described across devops roadmap reddit threads as the credential that most clearly signals real Kubernetes competence both because it is difficult and because it is a live, hands-on exam that cannot be passed by memorization alone
- "On the question of devops roadmap 2025 vs devops roadmap 2026 the core skills have not changed." Linux, Git, Docker, Kubernetes, AWS, CI/CD, Terraform. The specific versions of those tools update, new complementary tools emerge (Cilium for Kubernetes networking, OpenTelemetry for tracing), but the foundational sequence has been stable since approximately devops roadmap 2024. What has changed is the weight given to DevSecOps and Platform Engineering both have moved from "nice to have" to mainstream expectations.
- "Get cloud certified before applying." The practical advice for job-seekers is to complete at least one cloud certification before sending applications. It raises the chances of getting through automated ATS (Applicant Tracking System) screening significantly.
Common Mistakes on the DevOps Roadmap
Most people hit the same walls. Knowing about them helps you avoid them.
- Tutorial hell watching without building Hours of video content does not produce hands-on skill. Building does. Follow a tutorial once. Then close it and rebuild the same thing from scratch without it. That gap between "I followed along" and "I can do this independently" is where the real learning happens.
- Skipping Linux and networking Both come up constantly in production environments. Engineers who skip them struggle to debug the kinds of failures that happen at 2am on call where the only available tool is a terminal and your knowledge of how systems actually work.
- Trying to learn everything at once Docker + Kubernetes + AWS + Terraform + Jenkins simultaneously produces shallow knowledge of everything and mastery of nothing. Follow the phases. Finish one before starting the next.
- No public portfolio Your GitHub profile is your resume in DevOps. Hiring managers in Nepal and internationally look at it. Working CI/CD pipelines, Terraform modules, Kubernetes manifests, and documented projects are more convincing than a list of skills on a PDF. Build in public.
- Treating certification as a substitute for experience Certifications help. They are not sufficient on their own. The CKA is an exception it is hands-on enough to function as a genuine proof of skill. Multiple-choice certifications are screeners, not skill validators. Pair every certification with real project experience.
- Ignoring cost optimization early Cloud costs can spiral quickly. Building the habit of understanding what resources cost, using free tiers intelligently during learning, and cleaning up unused resources saves money during training and translates directly to senior-level skills around cloud cost optimization in production.
Future Directions: Where DevOps Heads After 2026
Platform Engineering
Platform Engineering is the emerging specialization directly above DevOps. Platform engineers build internal developer platforms self-service tools that let development teams deploy, monitor, and manage their own applications without requiring constant DevOps team involvement. Tools like Backstage (developer portals), Crossplane (Kubernetes-native infrastructure provisioning), and Port are at the centre of this movement. If you have strong Kubernetes and cloud skills, Platform Engineering is the natural next step.
DevSecOps at Scale
Security is no longer optional in the CI/CD pipeline. At scale, DevSecOps means automated policy enforcement, zero-trust networking, continuous compliance scanning against frameworks like SOC 2 and ISO 27001, and supply chain security (verifying that the open-source dependencies and container images you use have not been tampered with). This specialization commands a significant salary premium.
AIOps and AI-Assisted Pipelines
AI is entering DevOps workflows in practical, immediate ways. GitHub Copilot assists with writing Terraform modules and pipeline YAML. Datadog's AI features detect anomalies and suggest root causes before engineers notice problems. AI-assisted incident management can generate runbook suggestions from historical patterns. This does not eliminate DevOps engineers it shifts their time from manual investigation to higher-level system design and decision-making.
GitOps and eBPF
GitOps treats Git as the single source of truth for both application and infrastructure state. Changes to production happen by merging a pull request, not by running a script. Argo CD and Flux reconcile live cluster state to match Git continuously. This approach makes deployments auditable, reversible, and drift-free in ways that older imperative approaches cannot match.
eBPF (Extended Berkeley Packet Filter) is a lower-level technology that is rapidly transforming how networking, observability, and security work inside Linux systems. Cilium (Kubernetes CNI and network policy), Falco (runtime security), and Pixie (in-cluster observability) all build on eBPF. This is not beginner territory, but it is the direction that Kubernetes networking and observability are heading.
How to Pick the Right DevOps Course in Nepal
Not all training programs are equal. When evaluating a DevOps course in Nepal, look for these specific things:
- Hands-on lab time over lecture hours. A program that spends 80% of time on slides is not preparing you for a job. Look for programs where you build real infrastructure, not just watch demos.
- Current tool coverage. The DevOps course in Nepal should include Docker, Kubernetes, AWS, Terraform, and at least one CI/CD platform (GitHub Actions or GitLab CI). If Kubernetes is missing, the curriculum is out of date.
- Project-based assessment. Graduate with something to show working pipelines deployed to cloud, Kubernetes manifests in a public GitHub repository, documented infrastructure code a hiring manager can read.
- Employer connections. In Nepal's job market, warm introductions matter. Training providers with active employer networks give you an edge over applying cold.
- Instructor background. Instructors should have real DevOps engineering experience, not just teaching credentials. Ask about their professional background before enrolling.
At Skill Shikshya, the DevOps training in Nepal is built around the exact sequence in this guide Linux, Git, Docker, AWS, Terraform, Kubernetes, and CI/CD with hands-on projects from week one. Both in-person (Kathmandu) and online formats are available.
For the broader IT career picture, the complete IT career guide for beginners helps you understand where DevOps fits relative to other paths. And if you are still deciding, the guide on how to begin your DevOps career from scratch covers the honest starting sequence for complete beginners.
Conclusion: Start the Roadmap Today
The roadmap of a DevOps engineer in 2026 is the clearest it has ever been. Twelve phases, a specific set of tools, and a sequence that builds real, compounding skills from operating system fundamentals through to Kubernetes, service mesh, observability, and DevSecOps.
One question worth settling before you start: if you are weighing this path against a traditional software engineering track, our direct comparison of how DevOps engineering and software development differ in day-to-day responsibilities and career trajectory gives you an honest side-by-side breakdown.
The full path takes 8–12 months of consistent, hands-on effort. DevOps career paths in Nepal are paying between NPR 10 lakhs and NPR 60 lakhs annually at the local level and significantly more for engineers working remotely with international clients. The demand is real, the talent gap is real, and the jobs are being filled right now by people who started exactly where you are.
What do DevOps engineers do that changes year over year? The core is stable automate, monitor, deploy. What do DevOps engineers increasingly own is the full reliability lifecycle: from incident response through cost optimization to security policy. What makes the devops roadmap 2026 different from devops roadmap 2025 is not the foundational tools those are stable. It is the expectation that serious candidates understand Platform Engineering, bring DevSecOps habits, and have at least a passing familiarity with where AI fits into modern pipelines.
What is a DevOps engineer roadmap in practice? It is this article a 12-phase sequence from Linux through Kubernetes, monitoring, and security, applied with daily hands-on practice. Start with Linux. Build everything you learn. Put it on GitHub. Get one certification. Then get the next one. The rest follows from consistent effort applied in the right direction.
At Skill Shikshya, the best DevOps course Nepal has to offer is built around this exact path the hands-on DevOps training programme in Kathmandu is structured, project-based, and designed for both local and international remote roles. If you are ready to move forward, speak with a counsellor or enroll directly today.
Frequently Asked Questions
What is a DevOps roadmap in simple terms?
What is a DevOps engineer roadmap versus a general DevOps roadmap?
What is a DevOps engineer roadmap for 2024, 2025, and 2026 is there a difference?
Why devops is important for someone just entering IT?
What do devops engineers do that makes them hard to replace?
Is the devops career roadmap suitable for someone without a CS degree?
What is the scope of devops in Nepal for freshers in 2026?
How is the devops career roadmap different from a software engineer roadmap?
About Author:
